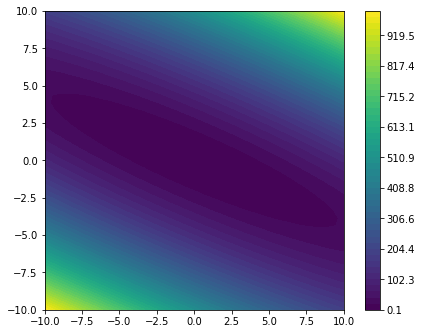Jekyll2024-04-12T12:49:15+02:00https://bonevbs.github.io/feed.xmlBoris BonevMy personal website.Boris BonevModeling Earth’s Atmosphere with Spherical Fourier Neural Operators2023-07-27T00:00:00+02:002023-07-27T00:00:00+02:00https://bonevbs.github.io/posts/sfnoBoris BonevA visual exploration of Gaussian Processes and Infinite Neural Networks2022-04-18T00:00:00+02:002022-04-18T00:00:00+02:00https://bonevbs.github.io/posts/gaussian-processesGaussian Processes (GPs) generalize Gaussian distributions to random variables that are functions (stochastic processes). As such, they are a powerful tool for regression and Bayesian inference. In the past years, they have received increased attention due to the interest in machine learning. An intriguing connection between GPs and neural network exists when the width of layers in feed-forward neural networks tends towards infinity. For a specific choice of the prior distributions that governs the network parameters, the resulting network will be a GP.
In this blog post, I intend to explore the connection between GPs and infinite neural networks, following the exposition in this ICLR article and adding some practical examples in the form of code and visuals. Moreover, I believe there is some value in building some intuition about GPs and how they can help us better understand neural networks (NNs). To this end, this article starts with a detailed introduction to Gaussian Processes. Readers familiar with the topic are encouraged to skip to the second part.
Finally, a few words on the code itself. The examples here are intended to be part of the text and I encourage the reader to copy the code and try out the examples. This is ideal for forming an intuitive understanding of the methods presented here. As programming language, I chose Julia, which has been an increasingly popular choice in scientific computing and machine learning. I took this opportunity to introduce interested readers to this exciting new language using practical examples. I hope that the simplicity and elegance of the language will speak for itself.
Recap of Gaussian distributions
Before we get started, we need to introduce GPs and motivate their use. To do so, we start with a short introduction of multivariate Gaussians and conditional Gaussians as we will make heavy use of them. Readers familiar with the topic may want to skip this introduction.
Multivariate Gaussian distributions
We introduce the multivariate Gaussian distribution, which is defined as
The parameters of the distribution are the mean $\mu \in \mathbb{R}^d$ and the covariance matrix $\Sigma \in \mathbb{R}^{d \times d}$. We can restrict our analysis to symmetric positive definite matrices $\Sigma$, as the antisymmetric part of $\Sigma$ does not contribute to the quadric form in the exponent.
Let us load some packages and then define a multivariate Gaussian in 2D. In Julia, we can make use of the Distributions package to do this.
usingLinearAlgebrausingRandom,DistributionsusingPlots# for plottingRandom.seed!(123)# this sets the random seed to 123, so that our code becomes reproducibletheme(:vibrant)# select the color theme for aesthetic reasons
We can visualize the resulting distribution and sample from it. Sampling from the distribution is as simple as x = rand(dist, n), which gives us n samples from dist. The syntax (x,y)->Distributions.pdf(dist,[x,y]) is used to extract the PDF of the distribution in its functional form for plotting.
Let us discuss conditional distributions. We stick to the common practice of distinguishing between random variables denoted by capital letters and their actual realizations denoted by lowercase letters. Assume $X \sim \mathcal{N}(\mu, \Sigma)$, where we have observed the first $k$ components $x_1, x_2, \dots, x_k$ of $X$. We are interested in knowing the conditional contribution $p(x_{k+1}, \dots, x_d \vert x_1, \dots, x_k)$ for the remaining, unobserved variables. For this purpose, let us partition the covariance matrix and the mean according to the variables:
Here, the subscript $a$ corresponds to the first $k$ entries, which are the observed entries, whereas $b$ corresponds to the remaining $d-k$ entries. One can show that the conditional distribution $p(x_{k+1}, \dots, x_d \vert x_1, \dots, x_k) = p(x_b \vert x_a)$ is a multinomial Gaussian itself, i.e.
where $\mu_{b\vert a}, \Sigma_{b\vert a}$ are the parameters of the conditional distribution. By inserting the partitioned variables and re-shuffling the terms in the exponent, we find that $\mu_{b\vert a}$ is determined by the conditioned mean
The attentive reader may recognise this as the Schur complement, which appears when the blocked covariance matrix $\Sigma$ is factored and the degrees of freedom corresponding to $a$ are factored out.
Marginalization of Gaussians
We have seen that the conditional distribution of a multivariate Gaussian is another multivariate Gaussian as well. Another nice property applies to marginal distributions. We recall that the marginal distribution over $x_b$ is obtained by intergrating out $x_a$. One can show that after inserting the partitioned Gaussian, one finds the satisfying result
Gaussian Processes as generalizations of multivariate Gaussians
Now that we have seen how the Gaussian distribution is generalized to $d$ dmensions, we may ask: “What if the random variable was a function?” This is where Gaussian Processes come in.
Gaussian Processes
Definition: For any index set $S$, a Gaussian Process (GP) on $T$ is a collection of random variables ${Y_x; \, x \in S}$, of which any finite subset $[Y_{x_1},Y_{x_2},\dots,Y_{x_k}]^T$ is a multivariate Gaussian.
In other words, for any number $k \in \mathbb{N}$ of samples taken at indices $x = [x_1,x_2,\dots,x_k]^T$, the random variables ${Y_{x_1},Y_{x_2},\dots,Y_{x_k}}$ jointly follow a multivariate Gaussian. This definition seems somewhat unpractical, thankfully however, we can prescribe the Gaussian Process by specifying functions $m(x)$ and $K(x,x’)$, such that
Informally, we can think of infinite dimensiona vectors being functions. For functions $f$ sampled from the GP, we simply write
\[f(x) \sim GP(m(x), K(x,x')).\]
We can think of this as the infinite variant of the marginalization property, as any finite subset of points will be described by the corresponding “marginalized” mean $m(x)$ and covariance matrix $K(x,x’)$.
Radial basis kernel
Let us explore some GPs. As we have pointed out, it suffices to specify a positive semi-definite kernel function and a mean. A popular kernel is the radial-basis function (RBF) kernel
where $\sigma$ is some parameter controlling the width of the kernel. Due to Julia’s functional nature, defining the RBF kernel is straight-forward.
sqexp_kernel(xa,xb;σ=1.0)=exp.(-[norm(a).^2forain(xa.-xb)]./(2.0*σ^2))# RBF kernel for matrix valued-inputs
sqexp_kernel (generic function with 1 method)
Let us write a routine for visualizing kernel functions.
function visualize_kernel(kernel;bounds=(-5,5))plot1=heatmap(LinRange(bounds[1],bounds[2],100),LinRange(bounds[1],bounds[2],100),kernel,yflip=true)xa=collect(LinRange(bounds[1],bounds[2],100))xb=zero(xa)plot2=plot(xa,kernel(xa,xb),label="K(x, 0)")plot(plot1,plot2,layout=@layout([a{1.0h}b]),size=(770,300))endvisualize_kernel(sqexp_kernel)
The figure on the right illustrates the kernel function $K(x, 0)$ at a fixed location $x’=0$. By varying $x’$, we slide the kernel across the domain of $x$. This implies that the covariance $K(x, x’)$ for any two points $x, x’$ will fall off exponentially with the distance squared.
Let us plot some realizations of the corresponding GP. Observing realizations is as easy as picking $n$ points on the real axis $[x_1, x_2, \dots, x_n]^T$ and observing $f(x_i)$ at these points. To simplify this, we set $m(x) = 0$. By the definition of GPs, we have that $[f(x_1), f(x_2), \dots, f(x_n)]^T \sim \mathcal{N}(0, \Sigma)$. In other words, we need to sample $n$ observations from the multivariate Gaussian $\mathcal{N}(0, \Sigma)$, where the covariance matrix $\Sigma$ is defined by $\Sigma_{ij} = K(x_i, x_j)$. The following code samples $10$ realizations from the Gaussian process defined by $m(x) = 0$ and the radial-basis kernel $K$.
function visualize_gp_samples(mean,kernel,nsamples;bounds=(0,1))mesh=LinRange(bounds[1],bounds[2],500)S=[kernel(xa,xb)forxainmesh,xbinmesh]# The following line is a fix to make sure that S is positive definite.# To do so, we define a threshhold tol and add the identity matrix to make this the new minimum eigenvalue.if!isposdef(S)S=S+(1e-12-min(eigvals(S)...))*IendGP=MvNormal(mean(mesh),S)# this is the workaround# sampling the distribution gives us divverent instance of the random variable fsamples=rand(GP,nsamples)plot(mesh,samples)endvisualize_gp_samples(zero,sqexp_kernel,10,bounds=(-4,4))
We observe that the ten samples are smoothly varying around the mean $0$. We have effectively created a distribution over some function space. For now, we are nto concerned with the precise properties of this function space. Rather, let us explore some other kernel functions.
Ornstein-Uhlenbeck process
Let us use Lagrange function, which resembles the functional form of the PDF that produces white noise. It is defined as
We observe that the kernel function is sharply peaked around $x’=0$. We use the same code as before to sample the Gaussian Process:
visualize_gp_samples(zero,exp_kernel,10)
We observe that the resulting function are not smooth everywhere and resemble realizations from a stochastic process. In fact, one can indeed show that the realizations that we observe are equivalent to the random walk of a Brownian particle subject to friction. This is also known as the Ornstein-Uhlenbeck process. It is evident that the smoothness properties of the resulting functions are related to the regularity (or lack thereof) of the kernel function.
Gaussian Process regression (Kriging)
We have seen some examples of GPs and are interested in what we can do with them. A powerful application for GPs is regression, which is also known as Kriging in this context. Let us assume that we have some measurements of a function $t(x)$ at points $x_i$ and that we would like to predict $t(x)$ everywhere else. Instead of measuring $t(x)$ directly however, we observe $Y = t(x) + \epsilon$ where $\epsilon \sim \mathcal{N}(0, \sigma^2)$ is a noise variable that adds uncertainty to the measurement. We could model this by prescribing the conditional distribution $p(y\vert x) = \mathcal{N}(y \vert t(x), \sigma^2)$. Alternatively, we can also interpret this as a Gaussian process $GP(t(x), \sigma^2 \delta(x-x’))$. $\delta(x-x’)$ denotes the Dirac delta, which adds uncorrelated noise for $x \neq x’$.
Let us make this more concrete. We choose $f(x) = \sin (x)$ and $\sigma = 0$. This gives us a deterministic outcome, as there will be no noise on the prior. We sample eight points at random from the interval $[- \pi, \pi]$, which will serve as our training points.
# sample observed points from the GPσ=0.0n_obs=8x_obs=rand(Uniform(-π,π),n_obs)S_obs=[dirac_kernel(xa,xb,σ=σ)forxainx_obs,xbinx_obs]if!isposdef(S_obs)S_obs=S_obs+(1e-12-min(eigvals(S_obs)...))*IendGP=MvNormal(f(x_obs),S_obs)f_obs=rand(GP,1)# plot the observationsscatter(x_obs,f_obs,label="observations",color=4)
After observing $k$ points from this Gaussian Process, we are interested in constructing a posterior distribution
\[Y \sim GP(m(x), K(x,x'))\]
Luckily, we can use conditional Gaussians to make a prediction on the query points. We assume that $x_1, x_2, \dots, x_k$ are the reference points, at which we have observed $y_1, y_2, \dots, y_k$, and $x_{k+1}, x_{k+2}, \dots, x_d$ the query points at which we would like to make a prediction $y_{k+1}, y_{k+2}, \dots, y_d$ using the GP posterior. As before, we will use the subscript $a$ to denote the first $k$ reference points and $b$ the remaining query points. By the definition of GPs, the vector $x$ follows
To make a prediction on the query points, all we need to do is compute the conditional Gaussian distribution and compute the required terms in $\Sigma$ and $\mu$. We make the simple choice of assuming a zero prior, such that $\mu_a = 0$. The terms in $\Sigma_{aa}$, $\Sigma_{ba}$ and $\Sigma_{bb}$ are computed by plugging the points $x_i$ into the Kernel. We rcall that the conditional Gaussian distribution is defined by
The maximum likelihood prediction in this case is given by the mean $\mu_{b\vert a}$ and the variance can be estimated by taking the diagonal entries of $\Sigma_{b\vert a}$. Let us visualize this with some code.
# compute the function of the posteriorfunction compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)Σaa=post_kernel(x_obs*ones(length(x_obs))',ones(length(x_obs))*x_obs')+prior_kernel(x_obs*ones(length(x_obs))',ones(length(x_obs))*x_obs')Σba=post_kernel(x_mesh*ones(length(x_obs))',ones(length(x_mesh))*x_obs')Σbb=post_kernel(x_mesh*ones(length(x_mesh))',ones(length(x_mesh))*x_mesh')# the regression partm=Σba*(Σaa\f_obs)# we assume μ=0 for the priorS=Σbb-Σba*(Σaa\Σba')returnm,Sendx_mesh=LinRange(-2*π,2*π,100)prior_kernel=(xa,xb)->dirac_kernel(xa,xb,σ=σ)post_kernel=(xa,xb)->sqexp_kernel(xa,xb,σ=1.0)m,S=compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)
The resulting mean and covariance matrix determine the distribution on all points of the domain. To visualize the posterior GP, we plot the mean and a confidence interval of $\pm 2 \sigma$. The latter can be extracted by taking the diagonal entries of the posterior covariance matrix.
# plot the posterior mean, as well as its 2σ confidence intervalvar=sqrt.(diag(S))plot(x_mesh,m,ribbon=(2*var,2*var),fc=:green,fa=0.3,label="model",linewidth=2,legend=:bottomright,size=(770,300))plot!(x_mesh,f(x_mesh),label="target function")scatter!(x_obs,f_obs,label="observations",color=4)
This is very nice. Not only where we able to fit the data points, but we also got a posterior distribution, that gives us a confidence interval. Because the prior distribution was deterministic, there is no uncertainty around the observed points. However, in between these points we observe that the covariance increases. Moreover, the kernel that we chose encodes some regularity, which results in smooth realizations, if we were to sample this GP.
Let us now re-introduce noise into our prior. To this end, we set $\sigma = 0.1$, and adapt the GP prior accordingly. The modified GP is determined by
# sample new observed points from the GP with non-zero varianceσ=0.1S_obs=[dirac_kernel(xa,xb,σ=σ)forxainx_obs,xbinx_obs]if!isposdef(S_obs)S_obs=S_obs+(1e-12-min(eigvals(S_obs)...))*IendGP=MvNormal(f(x_obs),S_obs)f_obs=rand(GP,1)# take the same mesh, but adapt the prior to the new varianceprior_kernel=(xa,xb)->dirac_kernel(xa,xb,σ=σ)post_kernel=(xa,xb)->sqexp_kernel(xa,xb,σ=1.0)m,S=compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)# plot the posterior mean, as well as its 2σ confidence intervalvar=sqrt.(diag(S))plot(x_mesh,m,ribbon=(2*var,2*var),fc=:green,fa=0.3,label="model",linewidth=2,legend=:bottomright,size=(770,300))plot!(x_mesh,f(x_mesh),label="target function")scatter!(x_obs,f_obs,label="observations",color=4)
We observe very similar results, with the difference of there being some uncertainty around the observed points. This is nice, as we can clearly see that this method is robust with respect to the noise in the observed data. Unfortunately, this plot also shows one of the main limitations of this approach. We notice that at the boundaries of the domain there is no way to predict the true GP. As such, it converges to the prior, which has zero mean.
Comparison to Bayesian linear regression
In the setting of Bayesian linear regression, we fit the function with
\[f(x) = wx + b,\]
where the parameters $w, b \in \mathbb{R}$ follow the prior distributions $w \sim \mathcal{N}(0, \sigma^2_w)$ and $b \sim \mathcal{N}(0, \sigma^2_b)$, with corresponding hyperparameters $\sigma^2_w$ and $\sigma^2_b$. This also forms a Gaussian Process, which we can see by forming the covariance of $f$ evaluated on two points $x$ and $x’$, given by
polynomial_kernel (generic function with 1 method)
visualize_kernel(polynomial_kernel)
# take the same mesh, but adapt the prior to the new varianceprior_kernel=(xa,xb)->dirac_kernel(xa,xb,σ=σ)post_kernel=(xa,xb)->polynomial_kernel(xa,xb)m,S=compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)# plot the posterior mean, as well as its 2σ confidence intervalvar=sqrt.(diag(S))plot(x_mesh,m,ribbon=(2*var,2*var),fc=:green,fa=0.3,label="model",linewidth=2,legend=:bottomright,size=(770,300))plot!(x_mesh,f(x_mesh),label="target function")scatter!(x_obs,f_obs,label="observations",color=4)
Unsurprisingly, this is not a particularly good fit, as we are fitting the data with a linear function. Moreover the result looks very similar to what we could expect when we perform Bayesian regression. To see how both methods compare, let us take a few steps back and recall how we compute the estimator in a Bayesian regression setting. As we did previously, we assume $w \sim \mathcal{N}(0, \sigma^2_w)$ and $b \sim \mathcal{N}(0, \sigma^2_b)$. After observing the data $x_a, y_a$, the Maximum-Likelihood estimate (MLE) is given by
We have used $\varphi_i$ to denote the $p$ basis functions for some $p \in \mathbb{N}_0$. In the setting of polynomial regression, these could be the monomial basis functions $\varphi_i: x \rightarrow x^i$. The matrix $\Phi(x)$ is also called the design matrix or, in the case of polynomial basis functions, Vandermonde matrix. In our particular (linear) case, this matrix is
and acts as a regularization term, putting the noise variance $\sigma^2$ in relation to the hyperparameters $\sigma_b^2$, $\sigma_w^2$. To simplify matters, we set $\sigma_b^2 = \sigma_w^2 = \sigma_0^2$ and $\lambda = \sigma^2 / \sigma_0^2$.
We compare the MAP estimator to the GP prediction
\[\mu_{b\vert a} = \Sigma_{ba} (\Sigma_{aa} + \sigma^2 I )^{-1} y_a,\]
which looks similiar but is not quite the same. We recall that $\Sigma_{aa} = \Phi_a \Phi_a^T$, which for the GP is a $k \times k$ matrix, as opposed to the $p \times p$ matrix $\Phi_a^T \Phi_a$ which appears in the regression scenario. Using $\Sigma_{ba} = \Phi_b \Phi_a^T$ and the Sherman-Morrison-Woodbury formula, we can rewrite it as
This pleasing result is also called the push-through property. More importantly, it shows that the GP regression with a polynomial kernel is equivalent to Bayesian regression using a prior distribution on the parameters. In fact, this property is already hinted at, when we realized that the process by which we generate the data could be interpreted as a GP. As such, we have demonstrated that GPs offer a high amount of flexibility and can model a vide variety of problems. Moreover, the choice of kernel was the crucial step, which allowed us to model Bayesian regression using GPs. As such it is essential to construct kernels based on the properties we expect our functions to have.
Finally, there is an important practical difference to Bayesian regression. GPs are non-parametric, as there are no learned parameters. We have essentially skipped the step of remembering the parameters, and instead compute a prediction directly. Additionally, this comes at the cost of having to factorize a larger, $k \times k$ matrix.
Constructing Kernels from scratch
The polynomial kernel hinted at how a kernel function can be constructed to implicitly perform regression in some basis. According to Mercer’s theorem, we can represent positive definite covariance functions $K(x,x’)$ as an infinite expansion
It is evident that this representation of $K$ essentially corresponds to the eigendecomposition of a matrix. We can use this to derive a kernel for periodic basis functions, by inserting the Fourier expansion, which yields
periodic_kernel(xa,xb;l=1.0)=exp.(-[2.0*sin(0.5*norm(a))^2forain(xa.-xb)]./(l^2))# RBF kernel for matrix valued-inputsvisualize_kernel(periodic_kernel)
# take the same mesh, but adapt the prior to the new varianceprior_kernel=(xa,xb)->dirac_kernel(xa,xb,σ=σ)post_kernel=(xa,xb)->periodic_kernel(xa,xb,l=1.0)m,S=compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)# plot the posterior mean, as well as its 2σ confidence intervalvar=sqrt.(diag(S))plot(x_mesh,m,ribbon=(2*var,2*var),fc=:green,fa=0.3,label="model",linewidth=2,legend=:bottomright,size=(770,300))plot!(x_mesh,f(x_mesh),label="target function")scatter!(x_obs,f_obs,label="observations",color=4)
The additional information regarding the periodicity clearly healps the GP to generalize (extrapolate) better. We see that the uncertainty in the prediction has an interesting structure which follows the same periodicity as the kernel. As we have prescribed the periodicity, the uncertainty lies in the phase and amplitude of the solution.
Connection to Neural Networks
At the beginning of this article I promised to sketch the connection to neural networks. The analysis here follows this and this article and we will largely stick to the notation of the former. The overarching goal of this section is to better understand the parallels between infinite Neural Nets and the GPs that they are equivalent to, such that they may be better analyzed and understood.
We consider a deep, feed-forward neural network with $L$ hidden layers. Let us denote with $x \in \mathbb{R}^{d_\text{in}}$ the input vector to the network. The $i$-th component of the input to layer $l$ is denoted similarly as $x^{l}_i$. This input is computed by applying the non-linear activation $\phi$ to the $i$-th output of the previous layer, $z_i^{l-1}$. In other words, $z_i^l$ denotes the ouput of the $i$-th neuron, after applying the affine transformation and before applying the nonlinearity. This is summarizd as
where $W^l_{ij}, b_i^l$ are the parameters of layer $l$ and $x_j^{l-1}(x)$ is the output of the previous layer, with $x_j^{0}(x) = x_j$. We have explicitly expressed the dependence of the output in each layer on the input vector $x$. The output of the neural network is the vector $z^L(x)$, which is the output of the last affine transformation.
Shallow Networks and Gaussian Processes
Let us consider the simplified case of a “shallow” network with a single hidden layer, comprising $N^1$ neurons. In this case, we can express the neural network as
So far, we have not assumed any priors for the weight and bias parameters. In the following, we assume that in each layer $l$, bias parameters $b_i^l$ are drawn i.i.d. from a Gaussian distribution with zero mean and $\sigma_{b,l}^2$ variance. We assume the same for the weight parameters $W_{ij}^l$, which are drawn i.i.d. from a Gaussian distribution with zero mean and $\sigma_{W,l}^2$ variance.
We are interested in computing the expected outcome of $\mathbb{E}[z_i^1(x)]$ for a fixed input $x$. We observe that the output is the weighted sum of the $N_1$ activations and the bias parameter. Due to the weight and bias parameters $b_i^0, W_{ij}^0$ being i.i.d., we observe that $x_j^1$ and $x_{j’}^1$ will be independent for $j \neq j’$. Due to the linearity of the expected value and the independence of $x_j^1$ and $x_{j’}^1$, we can write
The last step is a consequence of $\mathbb{E}[W_{ij}^1] = 0$ and the independence between $x_j^1(x)$ and the parameters $W_{ij}^1$. A similar arguments holds for $\mathbb{E}[(W_{ij}^1 x_j^1(x))^2]$, which can be rewritten as
This term is bounded, if $x^1_j(x)$ is bounded as well. This is the case if for instance, we set the activation function to $\phi = \tanh$. Consequently, the variance of $z_i^1(x)$ is given by
By the multivariate CLT, this implies that in the limit of infinite network width $N_1 \rightarrow \infty$, the prior of $z_i^1(x)$ will converge to a Gausian distribution with mean zero and variance $\sigma_{b,1}^2 + N_1\sigma_{W,1}^2 V^1(x)$. Thus, by adopting $\sigma_{W,1} = \omega_{W,1} N_1^{-1/2}$, where $\omega_{W,1}$ is a new paramter, we obtain a prior with constant variance as the number of hidden units increases. More importantly, for any finite collection of inputs $x^{\alpha=1}, x^{\alpha=2}, \dots, x^{\alpha=k}$, the set ${z_i^1(x^{\alpha=1}), z_i^1(x^{\alpha=2}), \dots, z_i^1(x^{\alpha=k})}$ will be a multivariate Gaussian, which is precisely the definition of a GP.
Let us explore some shallow networks to get a feeling for the matter. We use the populer Julia library Flux to handle neural networks for us. To simplify manners, we set $\omega_{W,1} = \sigma_{W,0} = \sigma_{b,0} = 1$ and $\sigma_{b,1} = 0$. The following code generates a neural network, which is parametrized by weights and bias parameters drawn from the specified Gaussian priors.
usingFluxfunction shallow_network(;width=100,activation=tanh)# initialize the weights according to our prior DistributionsW0=reshape(rand(Normal(0,1),width*1),(width,1))b0=reshape(rand(Normal(0,1),width*1),(width))W1=reshape(rand(Normal(0,1.0/width),1*width),(1,width))# this is the layer in which we need to rescale the variance to ensure finite variance of the joint Gaussianb1=reshape(rand(Normal(0,0),1*1),(1))# this one is turned offreturnChain(Dense(W0,b0,activation),Dense(W1,b1,identity))end
shallow_network (generic function with 1 method)
This simple function will generate shallow networks, with the specified width. We can generate functions and access their parameters in the following manner:
nn=shallow_network(width=100)size(nn[2].W)
(1, 100)
Let us write a function to visualize some samples from this prior, much in the same way as we have visualized samples from GPs.
function visualize_nn_samples(generator,nsamples;bounds=(-5,5))mesh=LinRange(bounds[1],bounds[2],500)nns=[generator()foriin1:nsamples]graphs=[nns[i](collect(mesh'))'foriin1:nsamples]plot(mesh,graphs)endvisualize_nn_samples(()->shallow_network(width=100),10)
We observe that this results in smooth functions with a variation that is almost always concentrated in a region around $x=0$ with a width of roughly $\sigma_{b,0}/\sigma_{W,0}$. Outside of this regions, the functions are almost always constant. Moreover, by varying the amount of hidden units, we observe that the functions become increasingly complex.
We can generate all kinds of GPs depending on the activation function that we choose. The following examples shows the result for step activation functions. We observe that the resulting functions resemble Brownian motion, especially in the limit of many hidden units, which equates to many jumps.
visualize_nn_samples(()->shallow_network(width=10000,activation=sign),10)# using step functions as activations
To analyze neural networks with the tool of Gaussian processes, we need to determine their kernel function. More specifically, we are interested in finding the covariance for two inputs $x$ and $x’$. We have
For nearby values $x \approx x’$, the first terms have roughly the same value, whereas the last term denotes the expected squared difference between the values of a single hidden unit for $x$ and $x’$. For step activation functions, this difference will be either $0$ or $4$, depending on whether the step occurs between $x$ and $x’$. Moreover, the location of this step is approximately uniform in the local vicinity, which would imply that the probability of the step occuring between $x$ and $x’$ grows proportionally with $\vert x - x’ \vert$. As such, we can estimate
for nearby points $x$ and $x’$, which is characteristic with our previous observations for Brownian motion GP kernels. A similiar analysis can be carried out for $\tanh$ activation functions, which yields
for nearby points and aligns with the smoothness properties observed in our experiments. I skip the analysis and point the interested reader to the original technical report by Neil.
Deep Neural Networks and Gaussian Processes
We are interested in deep neural networks and their relation to GPs. We recall that the output of the $l$-th layer is computed as
Assuming that $z_i^{l-1}(x)$ is a GP with zero mean and covariance determined by $K^{l-1}$, we can show that $z_i^l(x)$ is equally a GP as $N_l$ tends towards infinity. As before, $z_i^l(x)$ is a sum of i.i.d. terms with bounded variance and zero mean, due to the zero mean of the weight priors. In this limit, ${z_i^l(x^{\alpha=1}), z_i^l(x^{\alpha=2}), \dots, z_i^l(x^{\alpha=k})}$ also follows a multivariate Gaussian, and $z_i^l(x)$ is a GP. As for the shallow networks, we can write the Kernel function as
where we have dropped the subscripts indicating the layer of the variances as we take them to be all equal to the variance in the first layer. The expactation $\mathbb{E}\left[ \phi(z_j^{l-1}(x)) \, \phi(z_j^{l-1}(x’)) \right]$ is slightly more complicated than in the shallow case, as we need to integrate over the Gaussian distributions governing the input variables $z_j^{l-1}(x)$ and $z_j^{l-1}(x’)$. As these are characterized by the kernel function of the previous layer $K^{l-1}(x,x’)$, we can summarize this last term as a function $F_\phi$ of $K^{l-1}(x,x’), K^{l-1}(x,x), K^{l-1}(x’,x’)$, which are the three terms that can appear in this computation:
We identify this as the polynomial Kernel from linear regression.
visualize_gp_samples(zero,polynomial_kernel,10,bounds=(-10,10))# P is the polynomial kernel which we defined for polynomial regression using GPs
We proceed to construct kernels for other layers recursively. For some nonlinearities, this requires numerical integration and an algorithm is outlined in the paper, which we will not explore here. We will rather focus on ReLU activation functions, which allow the Kernel to be computed analytically. In this case, the Kernel is given by
Let us implement a function to compute this kernel recusively.
function ReLU_kernel(xa,xb;σw=1.0,σb=1.0,L=1)Kl=polynomial_kernel(xa,xb,σw=σw,σb=σb)Kdiaga=polynomial_kernel(xa,xa,σw=σw,σb=σb)Kdiagb=polynomial_kernel(xb,xb,σw=σw,σb=σb)# careful with the transpose in the case of matrix valued functions#@show Kdiagforl=1:L# compute the angular values from the previous layerθ=acos.(Kl./sqrt.(Kdiaga.*Kdiagb))Kl=σb^2.+σw^2/(2*pi).*sqrt.(Kdiaga.*Kdiagb).*(sin.(θ).+(pi.-θ).*cos.(θ))# if you wonder about all the dots, this is to ensure that the functions are applied point-wise and so the output has the right dimensions# update diagonal entries for the next computationKdiaga=σb^2.+σw^2/(2*pi).*Kdiaga*piKdiagb=σb^2.+σw^2/(2*pi).*Kdiagb*piendreturnKlend
ReLU_kernel (generic function with 1 method)
Let us visualize this Kernel for a single layer, i.e. for the shallow case:
We observe that this kernel resembles a smoother version of the polynomial kernel. In fact, we can visualize this kernel for an increasing number of levels:
We observe that the kernel functions flatten out as the number of layers increase. This implies that a higher number of layer amounts to a more uniform correlation among all points. (The same is true if we vary $x’$, albeit the kernel will be asymmetrical).
Let us also sample functions from the GP characterized by this kernel function. We draw samples from the NNGP (the GP characterized by this kernel), and compare it to the NN samples drawn from the priors we previously defined for finite width, shallow ReLU networks.
plot1=visualize_nn_samples(()->shallow_network(width=10000,activation=relu),10)# samples drawn from width=10000 shallow network priorsplot2=visualize_gp_samples(zero,(xa,xb)->ReLU_kernel(xa,xb,L=1),10,bounds=(-5,5))# samples drawn from the corresponding GPplot(plot1,plot2,layout=@layout([a{1.0h}b]),size=(770,300))
As we would expect, samples from the NNGP prior closely resemble the samples of our finite-width neural network samples. The differences in scaling are mainly due to the different parameters that we have chosen for each layer in the finite width case.
Inference using NNGPs
Let us revisit GP regression, this time using the ReLU neural network kernel. As we have already defined the kernel function, it is straight-forward to apply it to the regression problem.
We re-use our previous problem of fitting noisy data from a sinusoidal function. We adapt it to the neural network setting by adding more training data:
# sample observed points from the GPσ=0.1n_obs=100x_obs=rand(Uniform(-π,π),n_obs)S_obs=[dirac_kernel(xa,xb,σ=σ)forxainx_obs,xbinx_obs]if!isposdef(S_obs)S_obs=S_obs+(1e-12-min(eigvals(S_obs)...))*IendGP=MvNormal(f(x_obs),S_obs)f_obs=rand(GP,1);
# take the same mesh, but adapt the prior to the new varianceprior_kernel=(xa,xb)->dirac_kernel(xa,xb,σ=σ)post_kernel=(xa,xb)->ReLU_kernel(xa,xb,σw=sqrt(1.6),σb=sqrt(1.0),L=1)m,S=compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)# plot the posterior mean, as well as its 2σ confidence intervalvar=sqrt.(diag(S))x_mesh=LinRange(-1.25*π,1.25*π,100)plot(x_mesh,m,ribbon=(2*var,2*var),fc=:green,fa=0.3,label="GP mean",linewidth=2,legend=:bottomright,size=(770,300))plot!(x_mesh,f(x_mesh),label="target function",size=(770,300))scatter!(x_obs,f_obs,label="observations",color=4,size=(770,300))
What does this tell us? So far, we have understood how sampling infinitely wide neural nets using certain priors can be understood as Gaussian processes. Once we perform GP inference with it, we are essentially computing the MAP estimator assuming the prescribed kernel functsion and mean functions for the prior and posterior. This is especially useful, as it not only gives us a prediction but also estimate the uncertainty of the prediction. Moreover, it represents the optimal choice in the maximum a posteriori setting, and can therefore be regarded as the optimal performance when distributions are assumed over the parameters of the infinite network. This resembles Bayesian neural networks, where bayesian inference is performed on the network weights. This potential connection has also been noted by Lee et al. and might present an interesting direction for exploration.
We can compare this result to the output of a shallow neural network trained on the same training data.
As we can see, the outcome differs slightly compared to the GP prediction, as it has less regularity. This can be partially attributed to the finite width of the network and the fact that training it will render many neurons dead, and therefore getting the model stuck in a local minimum. As mentioned previously, Bayesian neural network might present an interesting test case to compare this to.
What happens if we use more layers? We observe that the performance of the NNGP can be improved by increasing the number of layers. For this particular example, we observe the best performance using $L=9$ layers. We observe that the predictions using deeper finite networks resemple this prediction. This is not entirely surprising as the kernel will determine the functional form of our approximation. Thus, the question remains how much we can use the NNGP posterior to infer properties about trained networks. Another interesting question in this regard is whether NNGPs can be used to inform the choice of neural network architectures.
prior_kernel=(xa,xb)->dirac_kernel(xa,xb,σ=σ)post_kernel=(xa,xb)->ReLU_kernel(xa,xb,σw=sqrt(1.6),σb=sqrt(1.0),L=9)m,S=compute_gp_posterior(x_obs,f_obs,x_mesh,post_kernel,prior_kernel)# plot the posterior mean, as well as its 2σ confidence intervalvar=sqrt.(diag(S))plot(x_mesh,m,ribbon=(2*var,2*var),fc=:green,fa=0.3,label="GP mean",linewidth=2,legend=:bottomright,size=(770,300))plot!(x_mesh,f(x_mesh),label="target function",size=(770,300))scatter!(x_obs,f_obs,label="observations",color=4,size=(770,300))
While we have studied inference only with one-dimensional univariate functions, Lee et al. further compare the performance of NNGPs on Image data such as MNIST and CIFAR to networks trained on these datasets. The test accuracy of trained networks on these datasets approach the accuracy of the trained NNGP posterior, but is in most cases outmaatched by the NNGP. While it is possible that NNGPs represent a limit for the accuracy of the associated trained networks, it is unclear what role training plays in this picture.
The reason why this approach is interesting is that the achievable quality of approximations depends on the functional form of the approximating functions, as well as on the training. The former is rather well understood and can be studied using approximation theoretic methods. The training dynamics and how they relate to the initialization however, are a topic of much debate (see Frankle et al. (2019)). Neural Network GPs offer an interesting approach that considers the prior distributions on the weights and then computes the optimal solution in the MAP setting. As such, they may present a possible avenue towards a better understanding of the achievable performance when training neural networks.
Why aren’t NNGPs more popular? Our implementation of the $L$-layer ReLU GP kernel, already revealed a central problem. In order to do inference, we need to evaluate the kernel function for each pair $x^{\alpha}, x^{\beta}$, from both the training and query points. This is due to the non-parametric nature of GPs, which requires a computation that envolves the entire training dataset during inference. This is especially costly, considering that the kernel had to be built up recursively, layer by layer. This situation becomes even worse if multidimensional inputs and outputs are considered.
Conclusion
I hope I could give you an intuitive introduction to Gaussian Processes and shine some light on their connection to Neural Networks. As we have seen, they offer an interesting link between stochastic processes and neural networks in the limit of inifinite layer width. To the best of my knowledge, this connection has only recently been investigated to better understand the achievable accuracy by training neural networks that are initialized using some prior distribution on the parameters. In particular, it might be worth comparing trained Bayesian networks and NNGP posteriors to see whether there is a connection between the two.
While doing my research for this article, I stumbled across many interesting articles on the topic. You can find them listed below.
References
Lee J., Bahri Y., Novak R., Schoenholz S.S., Pennington J. and Sohl-Dickstein J. (2018). Deep Neural Networks as Gaussian Processes., ICLR 2018. openreview.net/pdf?=id=B1EA-M-0Z
Andersen M.S. and Chen T. (2020). Smoothing Splines and Rank Structured Matrices: Revisiting the Spline Kernel. SIAM Journal on Matrix Analysis and Applications. doi.org/10.1137/19M1267349
Further reading
A note on the Julia language: Julia is compiled just in time, which means that running the code in global scope as we do here tends to be slow. If you want to experience the speed of Julia, I encourage you to write the code into function and executing these more than once.
There is an interesting connection between Kernel matrices, spline interpolation and so-called rank-structured matrices. These matrices have a nice structure, with low-rank offdiagonal blocks. If you are interested in some futher reading, I strongly suggest reading this article.
I found this post by Bruno Magalhaes super useful to revise some of the basics regarding MAP estimators.
A helpful and very well written introduction to GPs can be found here.
]]>Boris BonevAn Introduction to Numerical Optimization with Python (Part 1)2021-12-17T00:00:00+01:002021-12-17T00:00:00+01:00https://bonevbs.github.io/posts/numerical-optimizationThis is the first post in a series of posts that I am planning to write on the topic of machine learning. This article introduces fundamental algorithms in numerical optimization. For now, this is the Gradient Descent and Netwon algorithm. I might extend it with momentum based methods and conjugate gradient methods in the future. All of the posts are essentially Jupyter notebooks that I will publish in this repository.
Introduction
Numerical optimization is an important tool in todays machine learning pipeline and optimization algorithms are often used as a black-box tool. Many problems boil down to the minimization (or maximization for that matter) of an objective function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ with respect to the input $x \in \mathbb{R}^d$. It is important to understand these algorithms and under which conditions they perform well, so that they may be applied.
We consider convex problems with sufficient regularity, such that a global minimum exists and so that gradient information may be used. Algorithms that use these properties can be broadly classified as either Line Search methods or Trust Region methods. The exposition here follows Nocedal and Wright, which is an excellent introduction to the topic. I am not aiming for mathematical rigor, nor for completeness. Rather, I would like to revise some of the key concepts myself and give a nice first introduction, complete with intuition and some working code.
Preparation
Before we explore some approaches, we need a differentiable function complete with gradient information. As we want make ourselves familiar with ML-relevant tools out there, we will make use of the library PyTorch and its auto-differentiation capabilities. As usual, numpy and matplotlib will be useful as well:
Disclaimer: the code in this article could be greatly simplified by just using numpy instead of PyTorch. If you are mainly interested in numerical optimization, I suggest to do this, as this will clarify the core concepts.
Let us define a two-dimensional objective function, which we will be minimizing.
d=2# random quadratic form
classquadratic_form(torch.nn.Module):def__init__(self,D_in):super().__init__()self.c=torch.randn(1)self.b=torch.randn(D_in,1)# we do not use these, however I kept them for completeness, if we want a general quadratic form.
self.A=np.random.standard_exponential((D_in,D_in))self.A=torch.from_numpy(self.A).float()self.A=self.A.T@self.A# to ensure that A is a symmetric matrix
defforward(self,x):y=torch.sum(x*(self.A@x),0)# - 2.0 * self.b.T @ x + self.c
returny
As we are using PyTorch, we can make use of auto-differentiation to evaluate the gradient information with respect to the input $x$. A nice introduction to autograd in PyTorch can be found here.
objective_function=quadratic_form(d)# getting the gradient
x0=torch.rand(2,1,requires_grad=True)f0=objective_function(x0)# forward pass
f0.backward()# after having computed one step, this will compute the gradient
print(x0.grad)
tensor([[0.5347],
[1.0804]])
Bingo! We will also need a function to visualize our minimizer:
defplot_minimizier(f,bounds=[-10,10,-10,10],trace=np.empty(0)):x=np.linspace(bounds[0],bounds[1],40,dtype=np.float32)y=np.linspace(bounds[2],bounds[3],40,dtype=np.float32)X,Y=np.meshgrid(x,y)grid=np.vstack((X.flatten(),Y.flatten()))Z=f(torch.from_numpy(grid))Z=np.reshape(Z.detach().numpy(),(40,40))plt.gca().set_aspect("equal")plt.gcf().set_size_inches(7.5,5.5)contourplot=plt.contourf(X,Y,Z,levels=np.linspace(np.amin(Z),np.amax(Z),50))cbar=plt.colorbar(contourplot)# plot a sequence of points to visualize the optimization process
trace=np.array(trace)iftrace.size!=0:plt.plot(trace[:,0],trace[:,1],'w.',linestyle='dashed')plt.show()
plot_minimizier(objective_function)
We observe that the objective_function is a quadratic form with its minimum located at $(0, 0)^T$.
Taylor’s theorem
To illustrate both approaches, let us start with Taylor’s theorem. Suppose that $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is continuously differentiable and that $p \in \mathbb{R}^d$. Then, we have that
\[f(x+p) = f(x) + \nabla f(x + tp)^T p,\]
for some $t \in (0,1)$. Furthermore, if $f$ is twice continuously differentiable,
for some $t \in (0,1)$. Here, we have introduced the vector-valued gradient $\nabla f$ and the $d \times d$ Hessian matrix $\nabla^2 f$.
The latter implies $f(x+p) < f(x)$ for $p = - \alpha \nabla f(x)$, if some sufficiently small $\alpha$ is chosen. We can therefore update $x$ sequentially, such that $f(x)$ keeps decreasing, thus converging to a minimum.
Line Search methods
This idea brings us to line-search methods. The core idea of Line Search method is to update the solution $x_k$ iteratively according to
\[x_{k+1} = x_k + \alpha_k p_k,\]
where $p_k$ is a descent direction (which is not necessarily the negative gradient) and $\alpha_k$ a certain step size. Ideally, this will result in a decreasing sequence
which converges to a certain minimum. These approaches are also called line-search methods, as we are looking for the minimum across the line defined by the search direction $p_k$. It is evident that convergence will depend on the specific choice of the descent direction $p_k$ and step size $\alpha_k$.
Gradient descent
The natural choice for $p_k$ is to take the direction of steepest descent $-\nabla f(x_k)$. Taking the appropriate step size is a more difficult problem to solve. This leaves the choice regarding the step size open. A popular strategy is the so-called backtracking line-search. At each iteration, the following algorithm will give us a step-size $\alpha$:
In other words, we start out with a certain step size $\alpha$ and decrease it iteratively until the condition
\[f(x_0 + \alpha p_0) \leq f(x_0) + \alpha c ||p_0||^2,\]
is satisfied. $\tau \in (0,1)$ and $c \in (0,1)$ are some control parameters, which determine the behavior of the method. $\tau \in (0,1)$ is some shrinkage parameter, which controls the decay of $\alpha$, which is replaced by $\tau \alpha$ at each iteration. The parameter controls the maximal step size, as $\alpha$ will satisfy the above condition, which is also known as the Armijo–Goldstein condition (insert reference and say something about convergence).
Now that we have a method for choosing a step size, we can proceed by iteratively updating
defgradient_descent(f,x0,alpham=1.0,tol=1e-6):# initialize the procedure
x=x0x.requires_grad=Truef0=f(x)f0.backward()p=-x.gradalpha=alpham# track the progress in trace
trace=[x.detach().numpy()]# iterate
k=0whilek<100andalpha>tol:# for the following steps, we do not wish to track gradient information
# to the end, we use torch.no_grad()
withtorch.no_grad():alpha=backtrack(f,x,p,alpham)x=x+alpha*ptrace.append(x.detach().numpy())x.requires_grad=Truef.zero_grad()f0=f(x)f0.backward()p=-x.gradk+=1# compute the Wolfe condition
returntracex0=torch.tensor([[10.],[10.]],requires_grad=True)trace=gradient_descent(objective_function,x0)
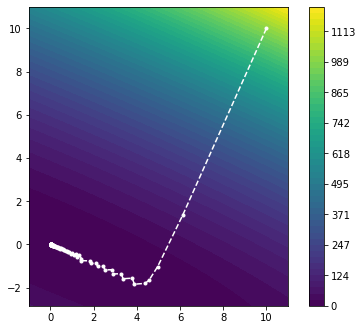
We run the iteration 100 times or until the step size becomes too small. This gives us the following output, which is a list containing each of the iterates $x_k$:
Very good! We can see that the updates are parallel to the gradient and move in the direction of steepest descent as we expected. Moreover, we observe that the step sizes $\alpha_k$ seem to be chosen reasonably, such that the method converges to the minimum. In fact, the Armillo-Goldstein condition with the chosen parameter is sufficient to guarantee convergence for a strictly convex function.
Let us now try another example, the Rosenbrock function $f(x_1, x_2) = (1-x_1)^2 + 100 (x_2 - x_1^2)^2$, which is a pathological example, with a narrow, curved valley. This proves to be difficult for gradient descent methods. Let us define the function and apply gradient descent:
# We also need a pathological case
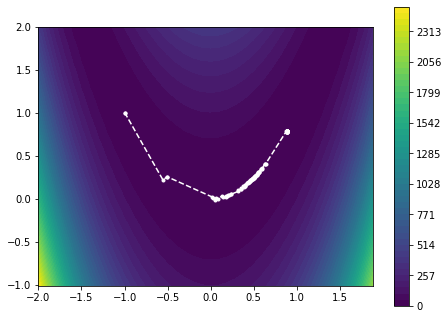
classrosenbrock_function(torch.nn.Module):def__init__(self):super().__init__()defforward(self,x):y=(1.0-x[0])**2+100*(x[1]-x[0]**2)**2returnyobjective_function=rosenbrock_function()x0=torch.tensor([[-1.],[1.]],requires_grad=True)f0=objective_function(x0)trace=gradient_descent(objective_function,x0)
We observe that many iterations are spent zig-zagging in the curved part of the solution. This is understandable, considering that the gradient-descent method is moving in the “wrong” direction and therefore has to adjust the descent direction frequently.
Trust region methods
The previous problem nicely illustrated the need for a smarter choice of the descent direction $p_k$. An alternative approach can be derived upon closer inspection of Taylor’s theorem. If $f$ has sufficient regularity, the function $f$ can be approximated locally around $x$ with the quadratic form
\[f(x+p) = f(x) + \nabla f(x)^T p + \frac{1}{2} p^T \, \nabla^2 f(x) \, p + \mathcal{O}(||p||^3).\]
By differentiating this with respect to $p$ and setting the result to zero, we find $\hat{p}$, which minimizes this quadratic form. $\hat{p}$ satisfies
\[\nabla^2 f(x) \, \hat{p} = - \nabla f(x),\]
which can be solved to obtain $\hat{p} = - (\nabla^2 f(x))^{-1} \nabla f(x)$.
Newton method
This gives rise to the Newton method. At each iteration, we compute the local quadratic approximation to $f$ and set $x_{k+1} = x_{k} + \hat{p}_k$ to be the minimizer of this local approximation. Coincidentally, this is equivalent tothe application of Newton’s method for root-finding to the Gradient $\nabla f(x)$, as we are essentially looking for a root of $\nabla f(x)$.
defnewton_method(f,x0):# initialize the procedure
x=x0x.requires_grad=True# track the progress in trace
trace=[x.detach().numpy()]# iterate
k=0whilek<20:# compute the gradient and Hessian
H=torch.autograd.functional.hessian(f,x,create_graph=False).squeeze()f0=f(x)f0.backward()# solve the linear system and compute the update
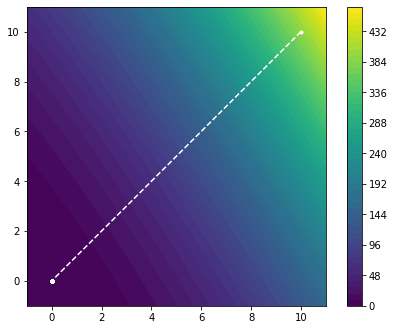
withtorch.no_grad():p=-torch.linalg.solve(H,x.grad)x=x+ptrace.append(x.detach().numpy())x.requires_grad=Truef.zero_grad()k+=1returntraceobjective_function=quadratic_form(d)x0=torch.tensor([[10.],[10.]],requires_grad=True)trace=newton_method(objective_function,x0)
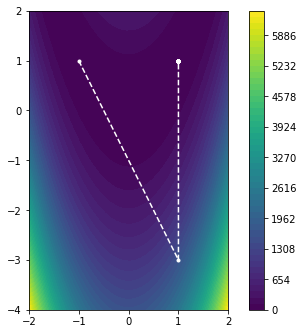
As we can see, the Newton method converged to the minimum in one step. This is hardly surprising as we have essentially approximated a quadratic form with a itself. As such, we find the global minimum in one step. Let us see how this method performs on the Rosenbrock function.
The Newton method converges to the desired solution in only two iterations, completely avoiding the previous problem. So, if the Newton method performs so well, why do we not always use it? The improved performance of the Newton method comes at the cost of evaluating the $d \times d$ Hessian matrix $\nabla^2 f(x)$ at each iteration and solving the linear system $\nabla^2 f(x) \, \hat{p} = - \nabla f(x)$. While this alone can be fairly prohibitive, there is also the question of regularity, as $f$ may not necessarily be smooth enough to have a Hessian everywhere. In other words, a local approximation with a quadratic form may not necessarily be a good approximation in such cases.
Some algorithms try to alleviate the former problem of having to form the Hessian by only approximating it. This can be done in the gradient descent approach, by keeping track of the chenge in the descent direction and using this information to approximate the Hessian. The latter problem of insufficient regularity can be addressed by switching between line search approaches and trust region methods depending on the local smoothness of $f$.
Conclusion
Numerical optimization is a fascinating field in its own which cannot be done justice in one article. There are many interesting aspects that we have not discussed, such as non-convex, non-smooth functions, as well as more sophisticated algorithms and the convergence properties of algorithms. In the following, I have included some references that I found useful, as well as references for further reading. Enjoy, and until next time!
References
Nocedal, J., & Wright, S. (2006). Numerical optimization. Springer Science & Business Media.